Love them or hate them. As a financial institution, you cannot but ensure that financial statements including the quarterly reports are filed in a timely manner. This has resulted in firms obsessing about the short cycles, often at the cost of long-term strategy and future planning. While it has been nearly 90 years since the Securities Exchange Act (SEA) of 1934 mandated the publication of these reports, there’s a madcap race to ensure that regulatory obligations are met every quarter.
Because there are several petabytes (one thousand million million (10 15 )) of data coming from disparate sources. Considering the time factor, there has often been the need to summarize these in the blink of an eye. That is a lot to ask for, if you are human.
But what if you are not?
For, if we go by recent trends including Generative AI, whenever and wherever (with due apologies to Shakira for pulling her song out of context) the human brain falters, artificial intelligence ups the stake.AI does job immutably in minutes by “slicing and dicing mammoths amounts of data” and generating a crisper summary than a French toast.
If that gets you thinking, that is quite like DeepSight. You are not wrong. So, here’s why FIs and FinTech’s need a platform like it (DeepSight).
Crisp and Clear are of the essence for Data Management for Financial Services!
Financial Services require information that is concise and transparent. In the fintech and financial services sector, the demand for concise and precise data is even greater. However, it is difficult for humans to extract meaningful data from large amounts of literature without significant investments and additional resources. Automation and AI can effectively handle this task. It is crucial for Financial Markets, Capital Markets, and FinTechs to generate relevant insights quickly and clearly, surpassing the speed of the scientific research community. The stakes are high, involving stakeholders, investors, regulators, and the market itself as a disruptive force. Real-time data, with its differentiating value, can be easily achieved through AI-enabled platforms.
● Nowadays, an enormous amount of data is generated, much of which remains isolated.
● As companies rapidly evolve and mergers and acquisitions take place, the data also undergoes swift changes.
● Furthermore, there are still legacy ecosystems that are fragmented, consisting of multiple workloads/IT systems, isolated databases, and lacking in master data.
However, with the implementation of Magic FinServ’s DeepSight, an exceptionally productive and intelligent rules-based platform, financial services organizations can receive clear, concise, and actionable insights to guide their decision-making.
But before this can happen, they must ensure they have high-quality data. Duplicate, inconsistent, and redundant data serves no purpose in the current context.
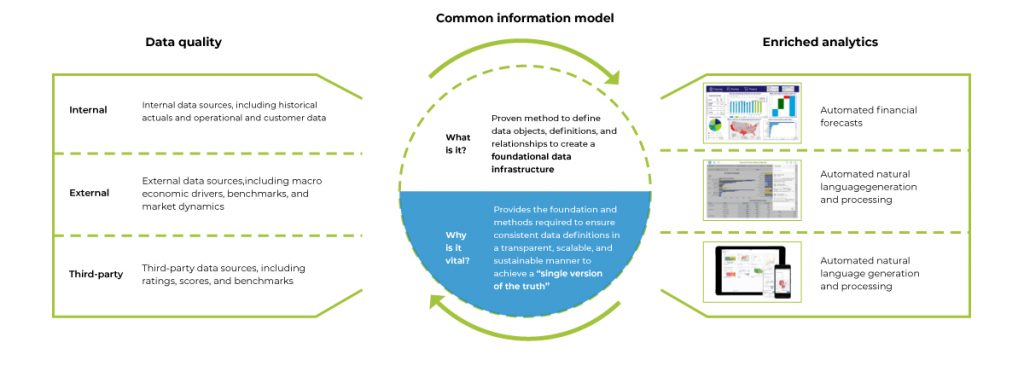
Therefore, it is essential to establish the definition and key attributes of good data.
What is good data?
According to decision-makers, good data is any data that is current, complete, and consistent. Good data is also that data that reflects the true picture of how the organization is performing. For financial services and capital markets, good data would mean real-time, and up-to-date data related to the performance of the asset classes that they handle on a day-to-day basis. It would also include data that would help asset managers and FinTech’s stay on course when it comes to adhering to the regulations and compliance measures while protecting the interests of the investor.
Doing something about getting good data
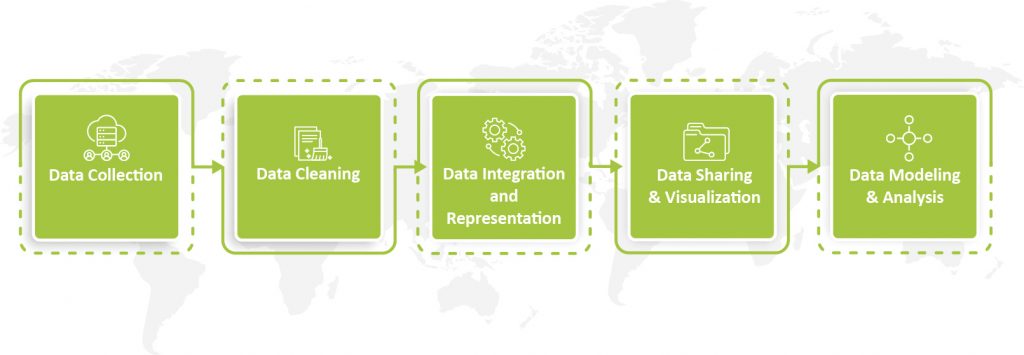
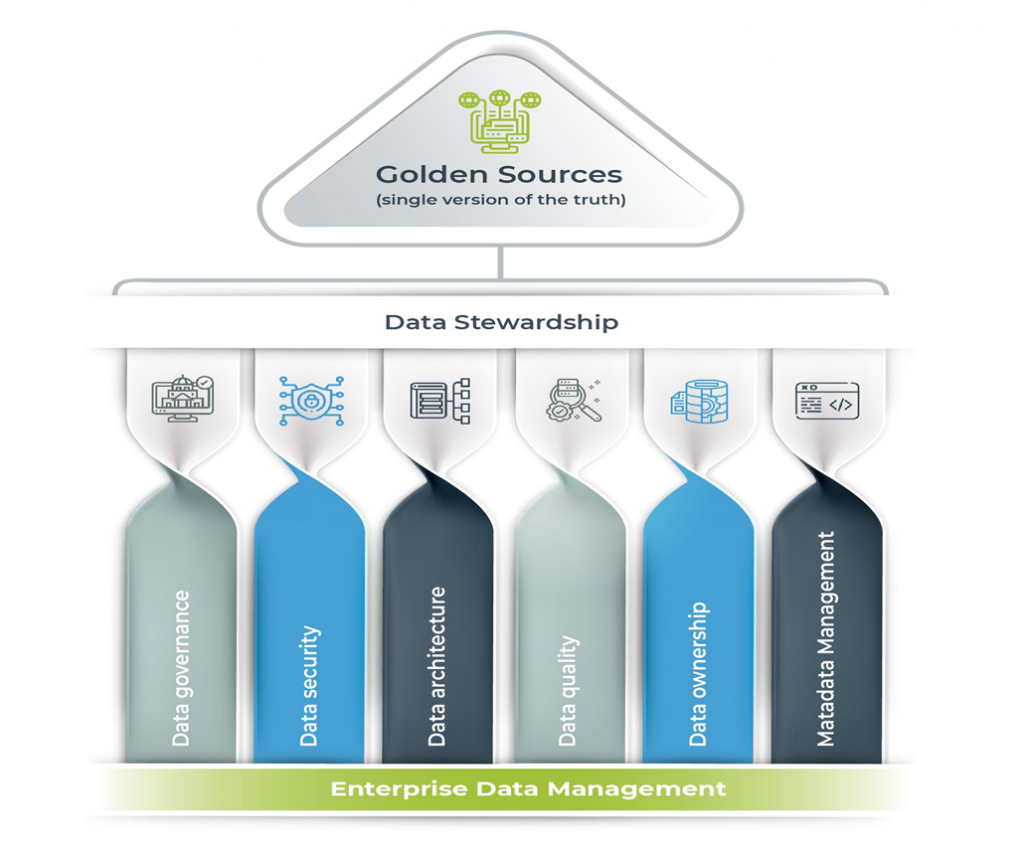
The problem of data management can be well explained by the fact that the data still occurs in silos. While executives want higher-quality data and smarter machine-learning tools to support them with demand planning, modeling, and solution strategies. But there is no getting there without first decluttering their data and breaking down data silos to establish a single source of truth. The first step obviously is to get the data out of the silos and declutter it while establishing a single source of truth, or slice, dice and ingest.
Carrying out slice, dice, and digest!
Slicing, dicing, and ingesting data from a single source of truth involves the process of gathering,arranging, and structuring data from different origins into a central repository. This repository serves as the authoritative and consistent version of the data throughout an organization. This method ensures that all stakeholders can access accurate and reliable information for analysis, reporting, and decision-making.
Fintechs and financial organizations have various critical and specialized data requirements. However, the data originates from multiple sources and exists in different formats. Therefore, it becomes necessary to slice and dice the data for precise reporting, compliance, Know Your Customer (KYC) processes, data onboarding, and trading. In portfolio management and asset monitoring, the speed at which data can be sliced, diced, and ingested is crucial due to strict timelines for regulatory reporting.Failure to adhere to these timelines can result in severe consequences such as the loss of a license.
Data is sliced, diced, and ingested through several methods including data consolidation and integration, data modeling and dimensional analysis, reporting and business intelligence tools, as well as querying and SQL for various activities such as accounts payable (AP), accounting, year-end tasks, KYC, and onboarding.
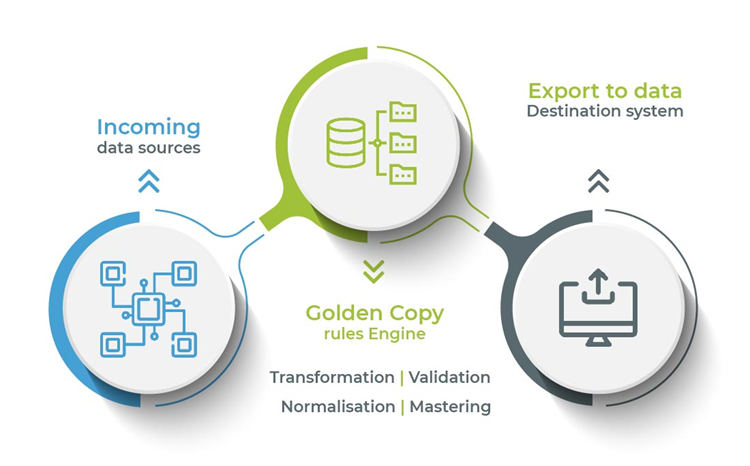
The Golden Copy: Here’s how DeepSight and Robust Data Management in Financial Services practices gets you there
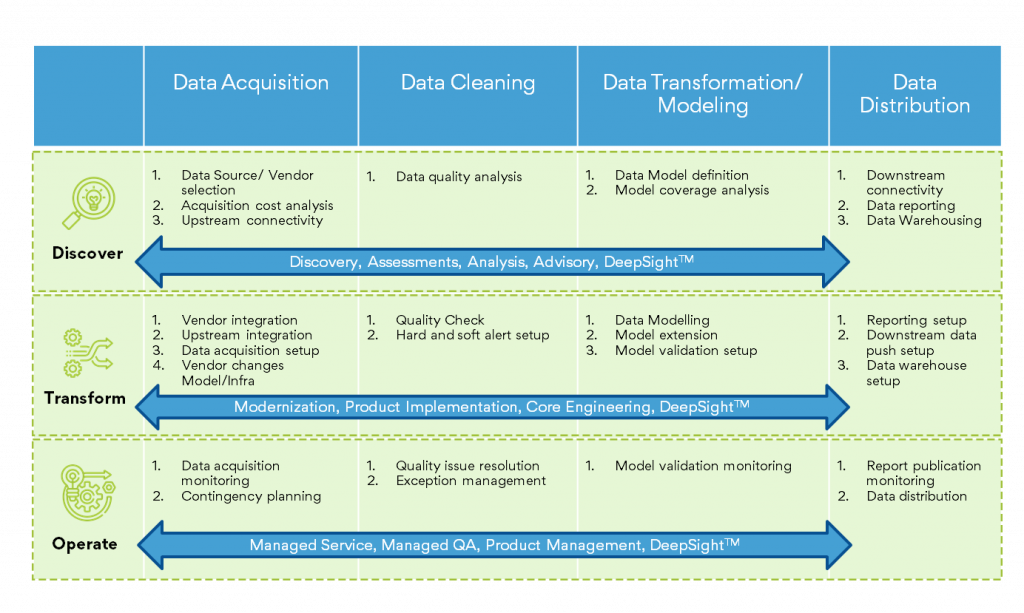
Here’s a brief on some of the techniques or steps involved in arriving at the single source of truth. Magic FinServ uses a combination of robust data management practices and intelligent platform for generating timely and actionable insights for accounts payable (AP), accounting, year-end activities, Know Your Customer (KYC), and onboarding.
Data Ingestion: Collection of data from different sources, databases, files, emails, attachments, APIs, websites, and other external systems. Data ingestion methods vary according to source – online, sequential, or batch mode to create a centralized location.
Data Integration: Once the data is ingested, it needs to be integrated into a unified format and structure. Data integration involves mapping and transforming the data to ensure consistency and compatibility. This step may include activities such as data cleansing, data normalization, standardization, and resolving any inconsistencies or discrepancies among the data sources.
Master Data Management: Creation of a reliable, sustainable, accurate, and secure data environment that represents a “single version of the truth.” In this step, the data is organized in a logical and meaningful way, making it easier to slice and dice the data for different perspectives and analyses.
Data Storage: The transformed and integrated data is stored in a centralized repository. Data Access and Querying: Once the data is stored in the centralized repository, stakeholders can access and query the data for analysis and reporting purposes. They can use SQL queries, analytical tools, or business intelligence platforms to slice and dice the data based on specific dimensions, filters, or criteria. This allows users to obtain consistent and accurate insights from a single source of truth. Asingle source of truth goes a long way in eliminating data silos, reducing data inconsistencies, and improving decision-making, while promoting data governance, data quality, and collaboration.
Now that we have uncomplicated the slice, dice, and data ingestion with DeepSight, another quick peek into how we have used DeepSight and Rules-based Approach to set matters straight.
Magic FinServ AI and rules-based approach for obtaining the single source of truth
Here are a few examples of how we have facilitated data management for financial services and data quality with the slice, dice, and ingest approach. Our proprietary technology platform DeepSight coupled with EDMC partnership has played an important role in each of the engagements underlined below.
Ensuring accurate reporting for regulatory filing: When it comes to regulatory filings, firms invest in an application to manage, interpret, aggregate, and normalize data from disparate sources, and fulfill their regulatory filing obligations. Instead of mapping data manually, creating a Master Data Dictionary using a rule & AI/ML-based Master Data provides accuracy, consistency, and reliability. Similarly, for data validation, a rule-based validation/recon tool for source data ensures consistency and creates a golden copy that can be used across enterprises.
Investment Monitoring Platform Data Onboarding: Existing investment monitoring platform for data onboarding was ensuring trade compliance by simplifying shareholder disclosure, sensitive industries, and position limit monitoring for customer holding, security, portfolio and trade files. The implementation team carried out the initiation, planning, analysis, implementation and testing regulatory filings. In the planning stage, we analyzed the customer’s data like Fund & reporting structure, Holdings, Trading regimes, Asset Types, etc., from a reference data perspective. Post the analysis, reference data is set up and source data are loaded. Thereafter, reference data is set up and source data is loaded once requisite transformations have been done. And now the positions data can be updated real-time with no hassle, and error-free.
Be sure where you stand relative to your data. Write to us for Financial Data Management solutions!
If you are not yet competing on data and analytics, you are losing on multiple fronts. We can ensure that data gets transformed into an asset and provide you with the head start you need. Our expertise encompasses a range of critical areas, including financial data management, data management in financial services, and tailored financial Data Management Solutions.
For more information, write to us at mail@magicfinserv.com.