Predictive Analysis – What it is?
Whenever you hear the term “Predictive Analysis”, a question pop-ups in mind “Can we predict the future?”. The answer is “no” and the future is still a beautiful mystery as it should be. However, the predictive analysis does forecast the possibility of a happening in the future with an acceptable percentage of deviation from the result. In business terms, predictive analysis is used to examine the historical data and interpret the risk and opportunities for the business by recognizing the trends and behavioral patterns.
Predictive analysis is one of the three forms of data analysis. The other two being descriptive analysis and Prescriptive analysis. The descriptive analysis examines the historical data and evaluates the current metrics to tell if business doing good; predictive analysis predicts the future trends and prescriptive analysis provides a viable solution to a problem and its impact on the future. In simpler words, descriptive analysis is used to identify the problem/scenario, predictive analysis is used to define the likelihood of the problem/scenario and why it could happen; prescriptive analysis is used to understand various solutions/consequences to the problem/scenario for the betterment of the business.
Predictive Analysis process
The predictive analysis uses multiple variables to define the likelihood of a future event with an acceptable level of reliability. Let’s have a look at the underlying process of Predictive Analysis:
Requirement – Identify what needs to be achieved
This is the pre-step in the process where it is identified what needs to be achieved (requirement) as it paves the ways for data exploration which is the building block of predictive analysis. This explains what a business needs to do more vis-à-vis what is being done today to become more valuable and enhance the brand value. This step defines which type of data is required for the analysis. The analyst could take the help of domain experts to determine the data and its sources.
- Clearly state the requirement, goals, and objective.
- Identify the constraints and restrictions.
- Identify the data set and scope.
Data Collection – Ask the right question
Once you know the sources, the next step comes in to collect the data. One must ask the right questions to collect the data. E.g. to build a predictive model for stock analysis, historic data must contain the prices, volume, etc. but one must also pay attention to how useful the social network analysis would be to discover the behavioral and sentiment patterns.
Data Cleaning – Ensure Consistency
Data could be fetched from multiple sources. Before it could be used, this data needs to be normalized into a consistent format. Normally data cleaning includes –
- Normalization
- a. Convert into a consistent format
- Selection
- a. Search for outliers and anomalies
- Pre-Processing
- a. Search for relationships between variables
- b. Generalize the data to form group and/or structures
- Transformation
- a. Fill in the missing value
Data Cleaning removes errors and ensures consistency of data. If the data is of high quality, clean and relevant, the results will be proper. This is, in fact, the case of “Garbage In – Garbage out”. Data cleaning can support better analytics as well as all-round business intelligence which can facilitate better decision making and execution.
Data collection and Cleaning as described above needs to ask the right questions. Volume and Variety are two words describing the data collection results, however, there is another important thing which one must focus on is “Data Velocity”. Data is not only required to be quickly acquired but needs to be processed at a good rate for faster results. Some data may have a limited lifetime and will not solve the purpose for a long time and any delay in processing would require acquiring new data.
Analyze the data – Use the correct model
Once we have data, we need to analyze the data to find the hidden patterns and forecast the result. The data should be structured in a way to recognize the patterns to identify future trends.
Predictive analytics encompasses a variety of statistical techniques from traditional methods e.g. data mining, statistics to advance methods like machine learning, artificial intelligence which analyze current and historical data to put a numerical value on the likelihood of a scenario. Traditional methods are normally used where the number of variables is manageable. AI/Machine Learning is used to tackle the situations where there are a large number of variables to be managed. Over the ages computing power of the organization has increased multi-fold which has led to the focus on machine learning and artificial intelligence.
Traditional Methods:
- Regression Techniques: Regression is a mathematical technique used to estimate the cause and effect relationship among variables.
In business, key performance indicators (KPIs) are the measure of business and regression techniques could be used to establish the relationship between KPI and variables e.g. economic parameters or internal parameters. Normally 2 types of regression are used to find the probability of occurrence of an event.
- Linear Regression
- Logistic Regression
A time series is a series of data points indexed or listed or graphed in time order.
Decision Tree
Decision Trees are used to solve classification problems. A Decision Tree determines the predictive value based on a series of questions and conditions.
Advanced Methods – Artificial Intelligence / Machine Learning
Special Purpose Libraries
Nowadays a lot of open frameworks or special purpose libraries are available which could be used to develop a model. Users can use these to perform mathematical computations and see data flow graphs. These libraries can handle everything from pattern recognition, image and video processing and can be run over a wide range of hardware. These libraries could help in
- Natural Language Processing (NLP). Natural Language refers to how humans communicate with each other in day to day activities. It could be in words, signs, e-data e.g. emails, social media activity, etc. NLP refers to analyzing this unstructured or semi-structured data.
- Computer Vision
Algorithms
Several algorithms which are used in Machine Learning include:
1. Random Forest
Random Forest is one of the popular machine learning algorithm Ensemble Methods. It uses a combination of several decision trees as a base and aggregates the result. These several decision trees use one or more distinct factors to predict the output.
2. Neural Networks (NN)
The approach from NN is to solve the problem in a similar way by machines as the human brain will do. NN is widely used in speech recognition, medical diagnosis, pattern recognition, spell checks, paraphrase detection, etc.
3. K-Means
K-Means is used to solve the clustering problem which finds a fixed number (k) of clusters in a set of data. It is an unsupervised learning algorithm that works itself and has no specific supervision.
Interpret result and decide
Once the data is extracted, cleaned and checked, its time to interpret the results. Predictive analytics has come along a long way and goes beyond suggesting the results/benefits from the predictions. It provides the decision-maker with an answer to the query “Why this will happen”.
Few use cases where predictive analysis could be useful for FinTech business
Compliance – Predictive analysis could be used to detect and prevent trading errors and system oversights. The data could be analyzed to monitor the behavioral pattern and prevent fraud. Predictive analytics in companies could help to conduct better internal audits, identify rules and regulations, improve the accuracy of audit selection thus reducing the fraudulent activities.
Risk Mitigation – Firms could monitor and analyze the operational data to detect the error-prone areas and reduce outages and avoid being late on events thus improving the efficiency.
Improving customer service – Customers have always been the center of business. Online reviews, sentiment analysis, social media data analysis could help the business to understand customer behavior and re-engineer their product with tailored offerings.
Being able to predict how customers, industries, markets, and the economy will behave in certain situations can be incredibly useful for the business. The success depends on choosing the right data set with quality data and defining good models where the algorithms explore the relationships between different data sets to identify the patterns and associations. However, FinTech firms have their own challenges in managing the data caused by data silos and incompatible systems. Data sets are becoming large and it is becoming difficult to analyze for the pattern and managing the risk & return.
Predictive Analysis Challenges
Data Quality / Inaccessible Data
Data Quality is still the foremost challenge faced by the predictive analyst. Poor data will lead to poor results. Good data will help to shape major decision making.
Data Volume / Variety / Velocity
Many problems in Predictive analytics belong to big data category. The volume of data generated by users can run in petabytes and it could challenge the existing computing power. With the increase in Internet penetration and autonomous data capturing, the velocity of data is also increasing at a faster rate. As this increases, traditional methods like regression models become unstable for analysis.
Correct Model
Defining a correct model could be a tricky task especially when much is expected from the model. It must be understood that the same model could be used for different purposes. Sometimes, it does not make sense to create one large complex model. Rather than one single model to cover it all, the model could consist of a large number of smaller models that together could deliver better understanding and predictions.
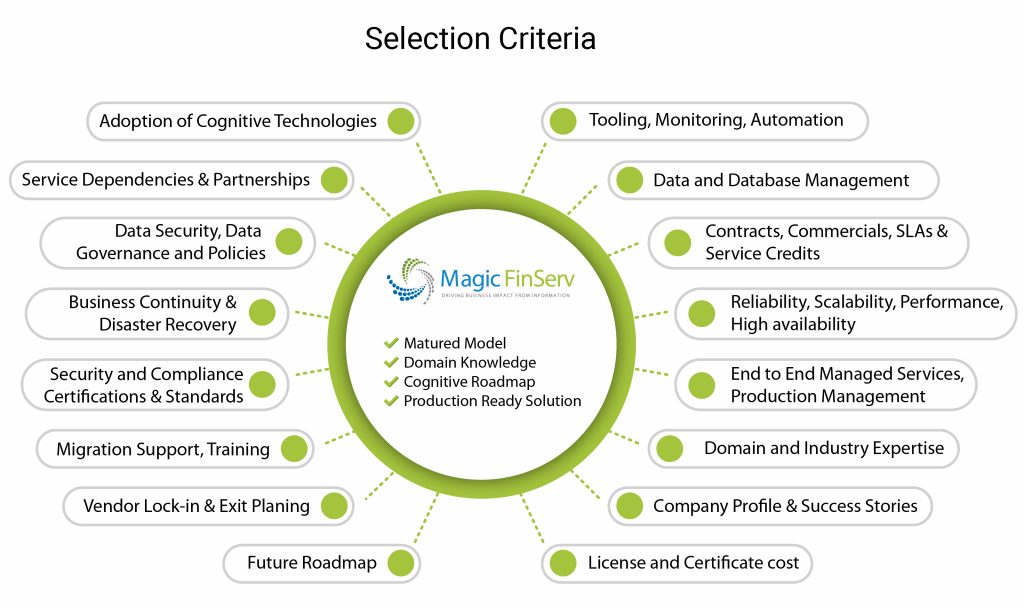
The right set of people
Data analytics is not a “one-man army” show. It requires a correct blend of domain knowledge with data science knowledge. Data Scientist should be able to ask the correct questions to domain experts in terms of what-if-analysis and domain experts should be able to verify the model with appropriate findings. This is where we at Magic FinServ could bring value to your business. At Magic FinServ we have the right blend of domain expertise as well as data science experts to deliver the intelligence and insights from the data using predictive analytics.
Magic FinServ – Value we bring using Predictive Analysis
Magic FinServ hence has designed a set of offerings specifically designed to solve the unstructured & semi-structured data problem for the financial services industry.
Market Information – Research reports, News, Business and Financial Journals & websites providing Market Information generate massive unstructured data. Magic FinServ provides products & services to tag meta data and extracts valuable and accurate information to help our clients make timely, accurate and informed decisions.
Trade – Trading generates structured data, however, there is huge potential to optimize operations and make automated decisions. Magic FinServ has created tools, using Machine Learning & NLP, to automate several process areas, like trade reconciliations, to help improve the quality of decision making and reduce effort. We estimate that almost 33% effort can be reduced in almost every business process in this space.
Reference data – Reference data is structured and standardized, however, it tends to generate several exceptions that require proactive management. Organizations spend millions every year to run reference data operations. Magic FinServ uses Machine Learning tools to help the operations team reduce the effort in exception management, improve the quality of decision making and create a clean audit trail.
Client/Employee data – Organizations often do not realize how much client sensitive data resides on desktops & laptops. Recent regulations like GDPR make it now binding to check this menace. Most of this data is semi-structured and resides in excels, word documents & PDFs. Magic FinServ offers products & services that help organizations identify the quantum of this risk and then take remedial actions.FacebookLinkedInTwitter