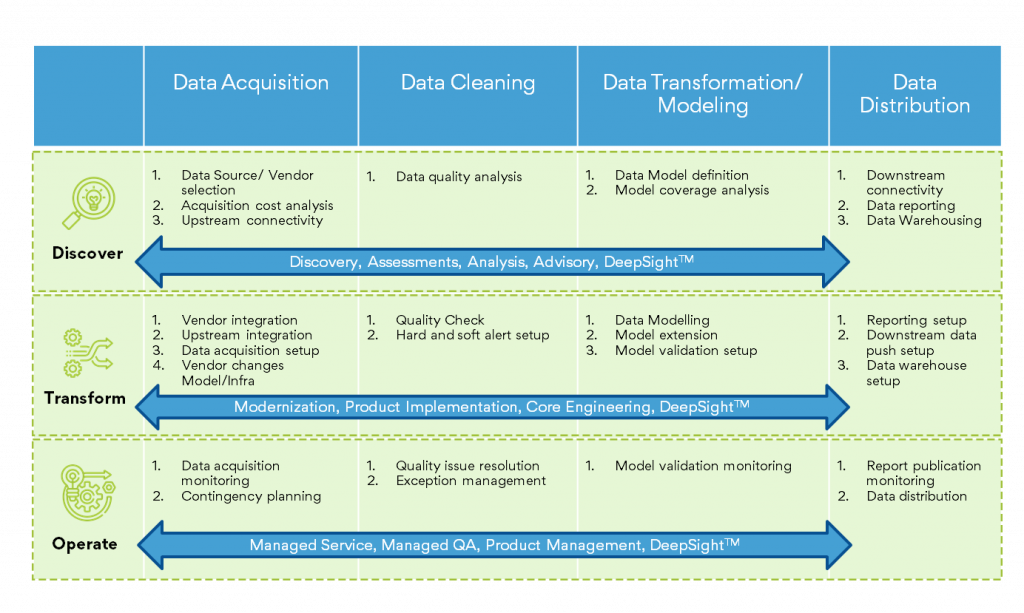
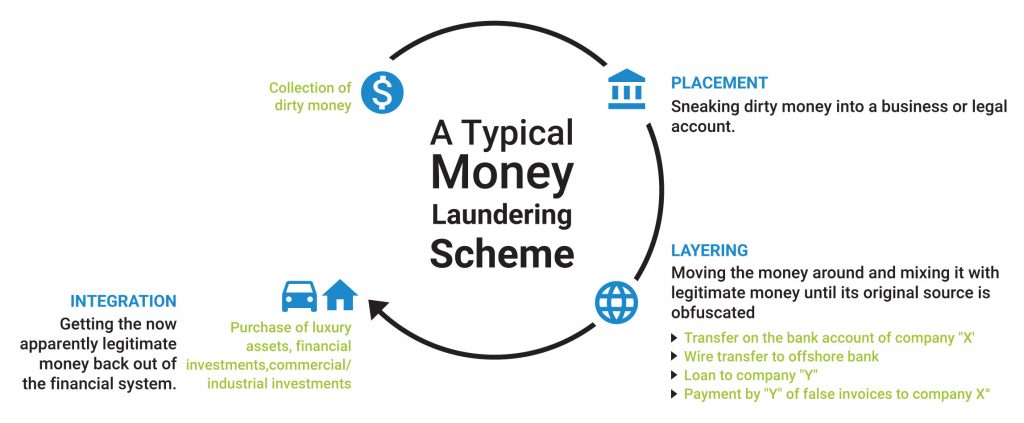
QA teams are struggling to maintain the balance between Time to Market and First Time Right. Time windows for QA are shrinking as release cycles become more frequent and On Demand. The move towards Digital Transformation is making this even more acute. Enter Risk-Based Testing.
The idea of risk-based testing is to focus on testing and spend more time on critical functions. By combining the focused process with metrics, it is possible to manage the test process by intelligent assessment and to communicate the expected consequences of decisions taken. Most projects go through extreme pressure and tight timescales coupled with a risky project foundation. With all these limitations, there’s simply no room for settlement on quality and stability in today’s challenging world, especially in the case of highly critical applications. So, instead of doing more with less and risking late projects, increased costs, or low quality, we need to find ways to achieve better with less. The focus of testing must be placed on aspects of the software that matter most to reduce the risk of failure as well as ensure the quality and stability of the business applications. This can be achieved by risk-based testing. The pressure to deliver may override the pressure to get it right. As a result, the testers of modern systems face many challenges. They are required to-
- Calculate software product risks. Identify and calculate, through consultation, the major product risks of concern and propose tests to address those risks.
- Plan and judge the overall test effort. Judge, based on the nature and scope of the proposed tests and experience, how expensive and time-consuming the testing will be.
- Obtain consensus on the amount of testing. Achieve, through consensus, the right coverage, balance, and emphasis on testing.
- Supply information for a risk-based decision on release. Perhaps the most important task of all is to provide information as the major deliverable of all testing.
The Association of Testing and Risk
There are three types of software risk:
- Product risk– A product risk is a chance that the product fails in relation to the expected outcome. These types of risks are related to the product definition, the product complexity, the lack of stability of requirements, and the potential defect-proneness of the concerned technology that can fail meeting requirements. Product risk is indeed the major part of concern of the tester.
- Process risk– process risk is the potential loss resulting from an improper execution of processes and procedures in conducting a Financial Institution’s day-to-day operations. These risks relate primarily to the internal aspects of the project including- its planning and scrutinizing. Generally, risks in this area involve the testers underestimating the complexity of the project and therefore not putting in the effort or expertise needed. The project’s internal management including efficient planning, controlling, and progress monitoring is the project management concern.
- Project risk– A project risk is an uncertain event that may or may not occur during a project. Contrary to our everyday idea of what “risk” means, a project risk could have either a negative or a positive effect on progress towards project objectives Such types of risk are related to the context of the concerned project as a whole.
The purpose of structured test methodologies tailored to the development activities in risk-based testing is to reduce risk by detecting faults in project deliverables as early as possible. Finding faults early, rather than late, in a project reduces the reworking necessary, costs, and amount of time lost.
Risk-based Testing Strategy
Risk-based testing – Objectives
- To issue relevant evidence showing that all the business advantages required from the systems can be achieved.
- To give relevant data about the potential risks involved in the release (as well as use) of the concerned system undergoing the test.
- To find defects in the software products (software as well as documentation) to make necessary corrections.
- To highlight and build the impression that the stated (as well as unstated) needs have been successfully met.
Risk-based test process – Stages
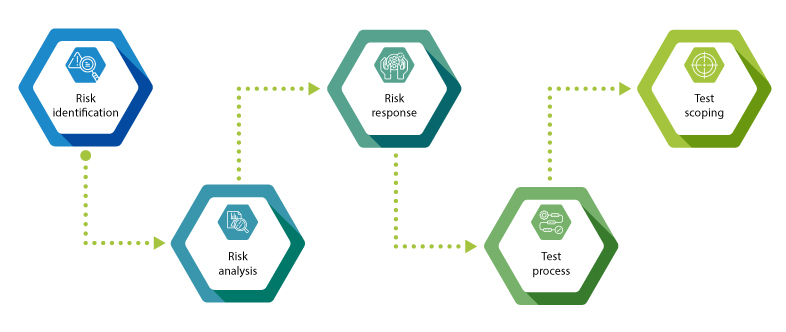
Stage 1: Risk Identification
Risk Identification is the activity that examines each element of the program to identify associated root causes that can cause These are derived from existing checklists of failure modes (most commonly) and generic risk lists that can be used to seed the discussions in a risk workshop. Developers, users, technical support staff, and testers are probably best placed to generate the initial list of failure modes. The tester should compile the inventory of risks from practitioners and input schedule the risk workshop, and copy the risk inventory to the attendees. Ensuring that adequate and timely risk identification is performed is the responsibility of the test manager or product owner is the first participant in the project.
Stage 2: Risk Analysis
Define levels of uncertainty. Once you have identified the potential sources of risk, the next step is to understand how much uncertainty surrounds each one. At this stage, the risk workshop is convened. This should involve application architecture from the business, development, technical support, and testing communities. The workshop should involve some more senior managers who can see the bigger picture. Ideally, the project manager, development manager, and business manager should be present.
Stage 3: Risk Response
The risk response planning involves determining ways to reduce or eliminate any threats to the project, and also the opportunities to increase their impact. When the candidate risks have been agreed on and the workshop is over, the tester takes each risk in turn and considers whether it is testable. If possible, the tester then specifies a test activity or technique that should meet the test objective. Typical techniques include requirements or design reviews, inspections or static analysis of code or components, or integration, system, or acceptance tests.
Stage 4: Test Scoping
A test scope shows the software testing teams the exact paths they need to cover while performing their application testing operations Scoping the test process is the review activity that requires the involvement of all stakeholders. At this point, the major decisions about what is in and out of scope for testing are made; it is, therefore, essential that the staff in the meeting have the authority to make these decisions on behalf of the business, the project management, and technical support.
Stage 5: Test Process
The process of evaluating a product by learning about it through experiencing, exploring, and experimenting, includes to some degree: questioning, study, modeling, observation, inference, etc. At this point, the scope of the testing has been agreed on, with test objectives, responsibilities, and stages in the overall project plan decided. It is now possible to compile the test objectives, assumptions, dependencies, and estimates for each test stage and publish a definition for each stage in the test process.
Conclusion
When done effectively, risk-based assessment and testing can quickly deliver important outcomes for an organization. Because skilled specialists assess risk at each stage of delivery, the quality of deliverables starts with the requirements.
Know how Magic FinServ can help you or reach out to us at mail@magicfinserv.com.